windows安装spark的具体方法 spark在windows中安装的详细教程
有些用户想要在windows操作系统中安装spark,但是不知道具体该如何操作才能安装,今天小编就给大家带来windows安装spark的具体方法,如果你刚好遇到这个问题,跟着小编一起来操作吧。
0、环境先给出安装好后的各个软件版本:
win10 64bitjava 1.8.0scala 2.12.8hadoop 2.7.1spark 2.4.1
1、java安装下载spark依赖java,首先电脑中必须安装java。
地址:https://www.oracle.com/java/technologies/javase-jdk8-downloads.html
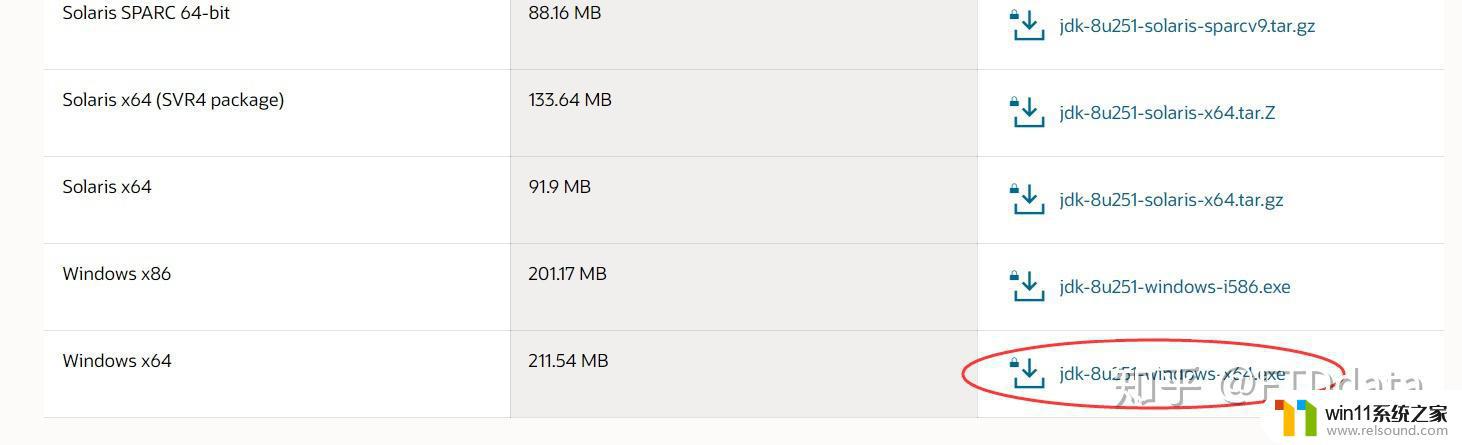
根据系统下载对应的jdk,下载后双击exe文件进行安装,可选择安装位置。
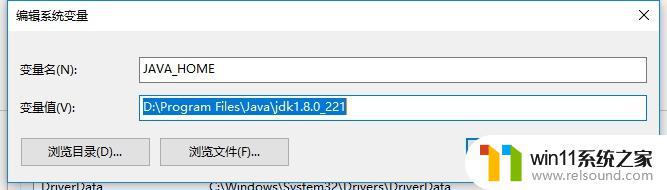
环境变量配置依次点击我的电脑 ->属性->高级系统设置->环境变量,在系统变量选项卡中。新建一个系统变量,如下,变量名为JAVA_HOME,变量值为本地安装java的路径。
添加好JAVA_HOME后,需要为Path变量增加值。选择Path变量(同样在系统变量中),点击编辑,弹出如下弹窗,新建两个值,分别为%JAVA_HOME%\bin和%JAVA_HOME%\jre\bin。
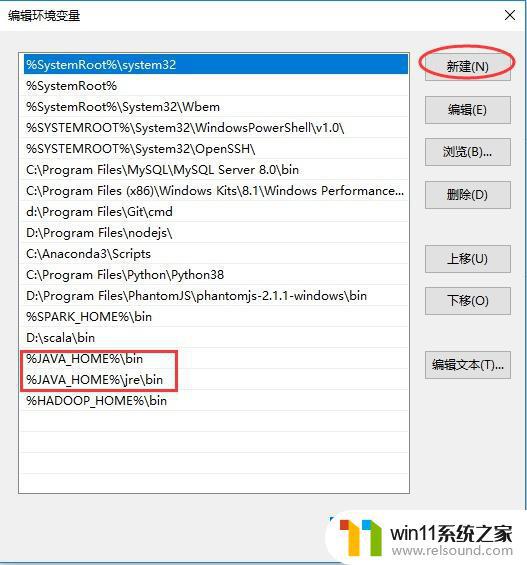
添加好后,确定、保存。
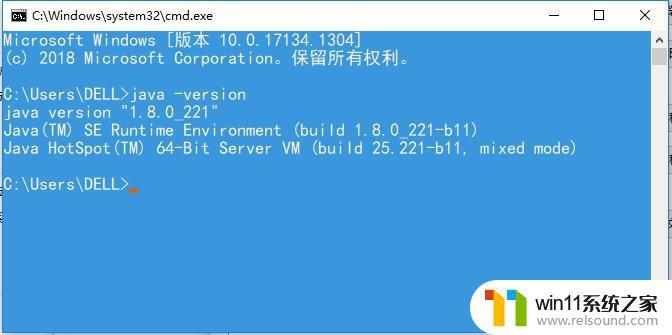
测试环境变量配置好后,测试java是否安装成功。win+R打开运行对话框,输入cmd命令进入命令行窗口,输入java -version查看java版本,有输出则说明java安装成功。
2、scala 安装下载spark是由scala语言编写的,需要安装scala。
地址:https://www.scala-lang.org/download/

根据系统下载对应的版本,进行安装,安装位置可自行选择。
环境变量配置同样,在系统变量的Path中,增加一个值,为scala的安装路径。
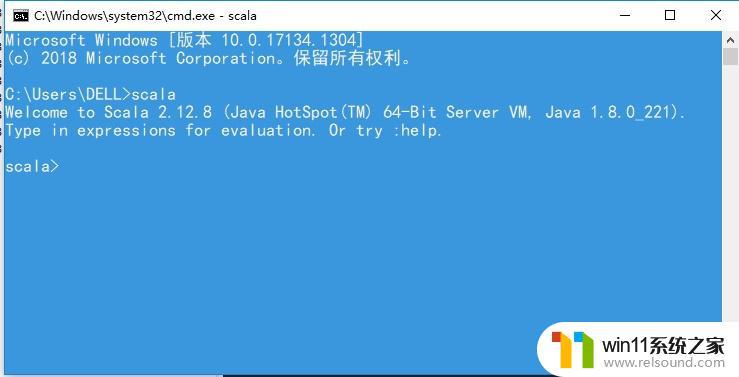
测试同样,打开命令行窗口,输入scala,出现如下界面表示安装成功。
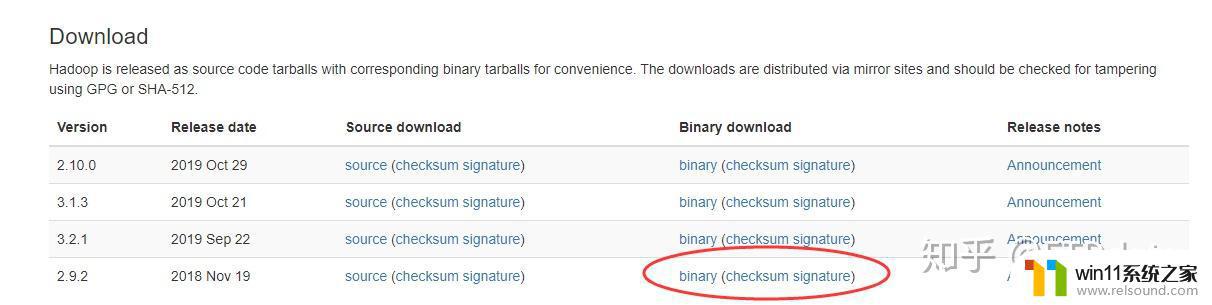
3、hadoop安装下载地址:http://hadoop.apache.org/releases.html
下载,安装到本地。
「需要注意的是hadoop的安装路径中不要有空格」,例如不要放在Program Files文件夹下。
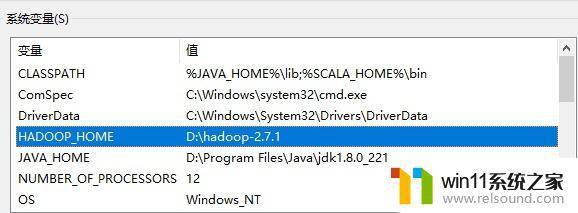
环境变量配置新增HADOOP_HOME系统变量,值为本地hadoop安装路径。
增加Path系统变量的值,为%HADOOP_HOME%\bin
4、spark安装下载下载地址:http://spark.apache.org/downloads.html
下载,然后本地安装。
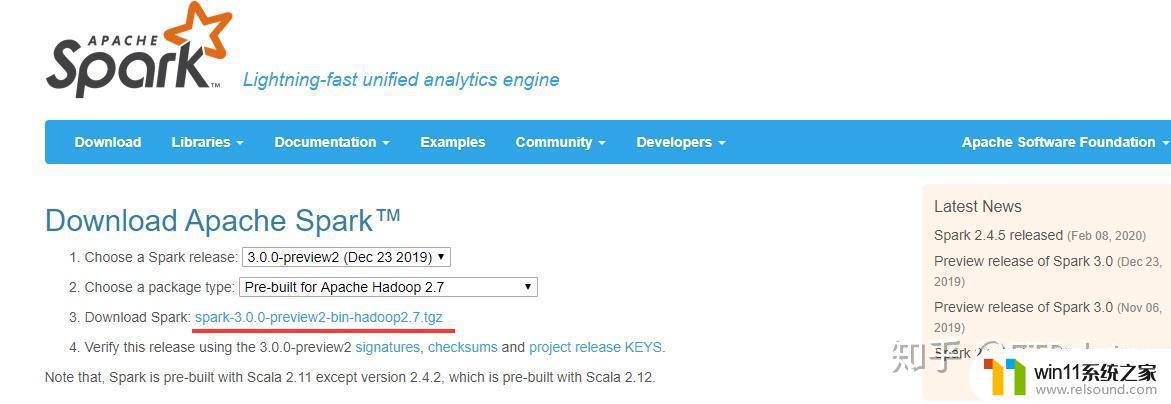
「需要注意的是spark版本需要和hadoop版本对应」,如界面所示的spark 3.0.0对应hadoop 2.7。
环境变量配置新增SPARK_HOME系统变量,值为本地spark安装路径。
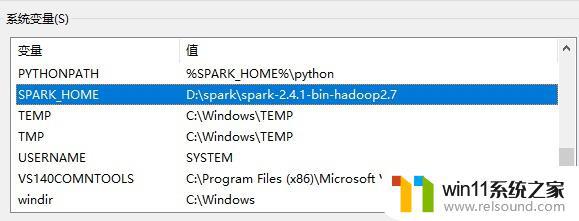
增加Path系统变量的值,为%SPARK_HOME%\bin。
测试在命令行窗口,输入spark-shell,出现如下界面,表示spark安装成功。

spark window单机版安装成功!单机版可以用来学习spark的基础使用,python用户可以用pyspark模块使用spark,R用于可以用SparkR包使用spark。
以上就是windows安装spark的具体方法的全部内容,有遇到相同问题的用户可参考本文中介绍的步骤来进行修复,希望能够对大家有所帮助。
windows安装spark的具体方法 spark在windows中安装的详细教程相关教程
- 微pe工具箱装win7详细教程 微pe工具箱怎么安装系统win7
- pe工具箱怎么装系统 微pe工具箱安装系统的教程
- 用gho镜像安装器安装系统教程 gho镜像安装器怎么装系统
- mac 装 windows的方法 苹果电脑怎么安装windows
- 神舟战神笔记本怎么安装win10 神舟战神重装win10系统官方教程
- win10怎么装win7双系统 win10安装双系统win7的教程
- 电脑怎样装win11系统 安装win11系统的三个方法
- 怎么安装windows7系统的步骤 电脑安装windows7系统步骤
- 华为笔记本装win10系统教程 华为笔记本如何安装win10系统
- windows10重装u盘怎么操作 u盘安装windows10系统全程图解
- win10影子系统怎么安装
- 软碟通做win10
- win10安装directx9.0
- win10安装软件报错
- 老电脑能装win10系统吗
- win10找不到无线网卡
系统安装教程推荐