AMD新推出AI加速卡MI300X:训练模型速度超英伟达H100,快60%

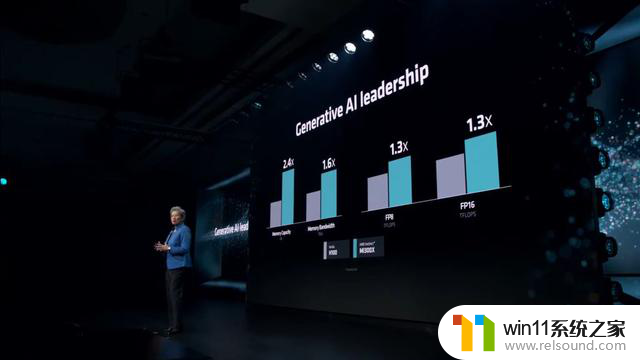
AMD 公司在演讲过程中,对比英伟达的 H100 加速卡,分享了 MI300X 的性能参数情况,附上数值如下:
内存容量是 H100 的 2.4 倍
内存带宽是 H100 的 1.6 倍
FP8 TFLOPS 精度是 H100 的 1.3 倍
FP16 TFLOPS 精度是 H100 的 1.3 倍
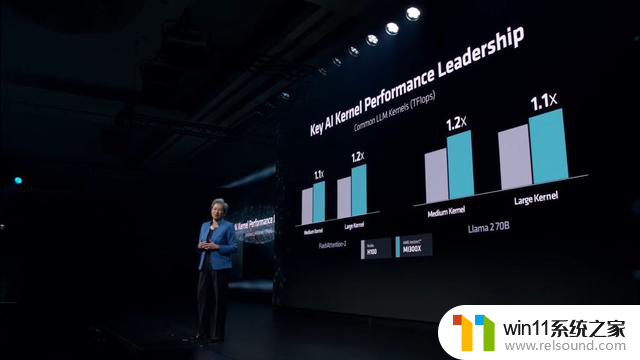
在 1v1 比较中,训练 Llama 2 70B 模型速度比 H100 快 20%
在 1v1 比较中,训练 FlashAttention 2 模型速度比 H100 快 20%
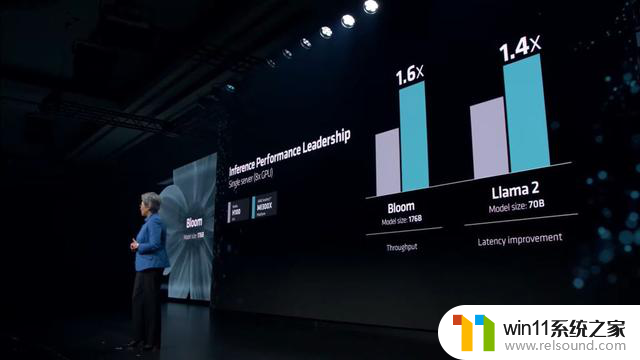
在 8v8 Server 比较中,训练 Llama 2 70B 模型速度比 H100 快 40%
在 8v8 Server 比较中,训练 Bloom 176B 模型速度比 H100 快 60%
AMD 提到,在训练性能方面,MI300X 与竞争对手(H100)不相上下,并提供具有竞争力的价格 / 性能,同时在推理工作负载方面表现更为出色。

MI300X AI 加速卡软件堆栈升至 ROCm 6.0,改善支持生成式 AI 和大型语言模型。



新的软件堆栈支持最新的计算格式,如 FP16、Bf16 和 FP8(包括 Sparsity)。
架构:AMD Instinct MI300X 是最受关注的芯片,因为它针对的是 AI 领域的 NVIDIA 的 Hopper 和英特尔的 Gaudi 加速器。
该芯片完全基于 CDNA 3 架构设计,混合使用 5nm 和 6nm IP,AMD 组合这些 IP,让其晶体管数量达到 1530 亿个。

设计方面,主中介层采用无源芯片布局,该芯片使用第 4 代 Infinity Fabric 解决方案容纳互连层。中介层总共包括 28 个芯片,其中包括 8 个 HBM3 封装、16 个 HBM 封装之间的虚拟芯片和 4 个有源芯片,每个有源芯片都有 2 个计算芯片。
每个基于 CDNA 3 GPU 架构的 GCD 总共有 40 个计算单元,相当于 2560 个内核。总共有八个计算芯片 (GCD),因此总共有 320 个计算和 20,480 个核心单元。在良率方面,AMD 将缩减这些内核的一小部分,我们将看到总共 304 个计算单元(每个 GPU 小芯片 38 个 CU),总共有 19,456 个流处理器。

内存方面,MI300X 采用 HBM3 内存,容量最高 192GB,比前代 MI250X(128 GB)高 50%。该内存将提供高达 5.3 TB / s 的带宽和 896 GB/s 的 Infinity Fabric 带宽。
AMD 为 MI300X 配备了 8 个 HBM3 堆栈,每个堆栈为 12-Hi,同时集成了 16 Gb IC,每个 IC 为 2 GB 容量或每个堆栈 24 GB。
相比之下,NVIDIA 即将推出的 H200 AI 加速器提供 141 GB 容量,而英特尔的 Gaudi 3 将提供 144 GB 容量。
在功耗方面,AMD Instinct MI300X 的额定功率为 750W,比 Instinct MI250X 的 500W 增加了 50%,比 NVIDIA H200 增加了 50W。
其中一种配置是技嘉的 G593-ZX1 / ZX2 系列服务器,提供多达 8 个 MI300X GPU 加速器和两个 AMD EPYC 9004 CPU。这些系统将配备多达 8 个 3000W 电源,总功率为 18000W。





AMD新推出AI加速卡MI300X:训练模型速度超英伟达H100,快60%相关教程
- 硬刚英伟达AI芯片:AMD推出GPU“加速器”MI300,提升AI计算能力
- 英伟达推出游戏定制化AI模型代工服务,助力芯片巨头加速AI重磅产品发展
- 大模型晚报|NVIDIA宣布推出DGX GH200人工智能超级电脑助力AI模型训练
- 英伟达AI超级芯片全面投产,加速AI大模型及超算市场占领
- 英伟达推出史上最强AI服务,速度飙升省钱双赢!
- 英伟达认为:GPU训练大语言模型成本可降低96%
- 英伟达与联发科合作推出新处理器,手机加速效果再升级!
- AMD推出全新MI300系列AI芯片,与英伟达抢占AI芯片高地
- 英伟达推出AI模型代工服务为NPC注入“灵魂”
- iPhone上本地每秒生成12个tokens,微软发布phi-3-mini模型,加速AI模型部署速度
- 英伟达新一代AI芯片过热延迟交付?公司回应称“客户还在抢”
- 全球第二大显卡制造商,要离开中国了?疑似受全球芯片短缺影响
- 国外芯片漏洞频发,国产CPU替代加速,如何保障信息安全?
- 如何有效解决CPU温度过高问题的实用方法,让你的电脑更稳定运行
- 如何下载和安装NVIDIA控制面板的详细步骤指南: 一步步教你轻松完成
- 从速度和精度角度的 FP8 vs INT8 的全面解析:哪个更适合你的应用需求?
微软资讯推荐
- 1 英伟达新一代AI芯片过热延迟交付?公司回应称“客户还在抢”
- 2 微软Win11将为开始菜单/任务栏应用添加分享功能,让你的操作更便捷!
- 3 2025年AMD移动处理器规格曝光:AI性能重点提升
- 4 高通Oryon CPU有多强?它或将改变许多行业
- 5 太强了!十多行代码直接让AMD FSR2性能暴涨2倍多,性能提升神速!
- 6 当下现役显卡推荐游戏性能排行榜(英伟达篇)!——最新英伟达显卡游戏性能排名
- 7 微软发布Win11 Beta 22635.4440预览版:重构Windows Hello,全面优化用户生物识别体验
- 8 抓紧升级Win11 微软明年正式终止对Win10的支持,Win10用户赶紧行动
- 9 聊聊英特尔与AMD各自不同的CPU整合思路及性能对比
- 10 AMD锐龙7 9800X3D处理器开盖,CCD顶部无3D缓存芯片揭秘
win10系统推荐