NVIDIA GeForce RTX 4080 FE公版首发评测:ADA架构第二发炮弹如何表现?
1序言
2022年11月16日晚点22点,NVIDIAGeForceRTX4090显卡正式解禁。NVIDIA对新品发布的节奏把控的确是紧得很,距旗舰产品GeForceRTX4090发布后一个月,正式解禁包括GeForceRTX408016GBFounderEdition和AIC版的评测与开箱部分,明天就能正式开卖此款显卡。而此两款旗舰级显卡的陆续到似乎也是向对手的一种示威,毕竟部品新显卡也是纸面发布不久,下个月正式解禁的样子。

说回正题,此次我们收到了多家的GeForceRTX408016GB非公版产品,同时也收到来NVIDIA寄回过来的GeForceRTX408016GBFounderEdition(简称“RTX408016GBFE”),而此次测试我们也将会以RTX408016GBFE性能为基准,为大家测试一下此款RTX4080FE性能到底如何?
规格对比
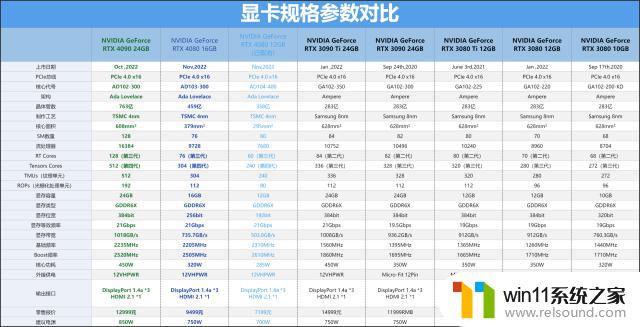
与往常一样,我们先来看看RTX408016GBFE的规格,这个规格表其实早在RTX4090FE发布之时就已经做好了,不过RTX408012G这个产品就真正式更名了,那之后是RTX4070Ti还是RTX4070这个就真的之后再另说了。
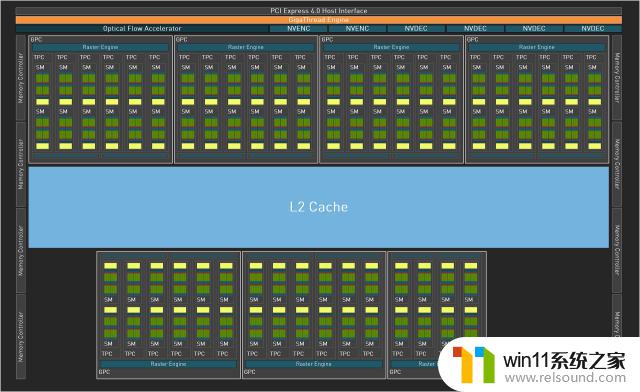
AD103FullChipDiagram
RTX408016GBFE,核心代号AD103-300,是继AD102后的第二个AdaLovelace架构核心,采用了中型核心的设计,从规格上来看并没有AD102那样的庞大。一个完整规格的AD103核心包括了7个GPC(图形处理集群)、40个TPC(纹理处理集群)、80个SM(流式多处理器)和⼀个带有8个32Bit显存控制器的256Bit显存位宽。
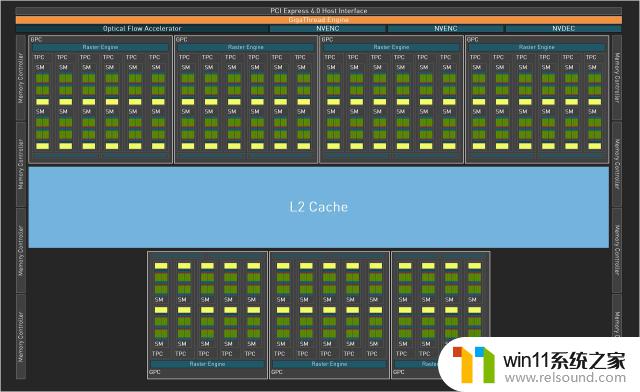
GeForceRTX408016GB
而从上面的两个GPU架构图,你应该懂了些什么,对的,RTX408016GB与RTX4090一样并非采用了完整规格的核心,其同样内置了7个GPC单元,但是TPC数量进行了一定的削减,保留38个TPC,这样SM单元为76个,9728个CUDA核心,显存位置同样保持在256Bit上。只不过NVDEC(视频解码器;【NVENC,视频编码器】)数量也从完整的4个减成了1个,那是否意味着视频解码方面有一定的减弱?之后我们再来测试一下。
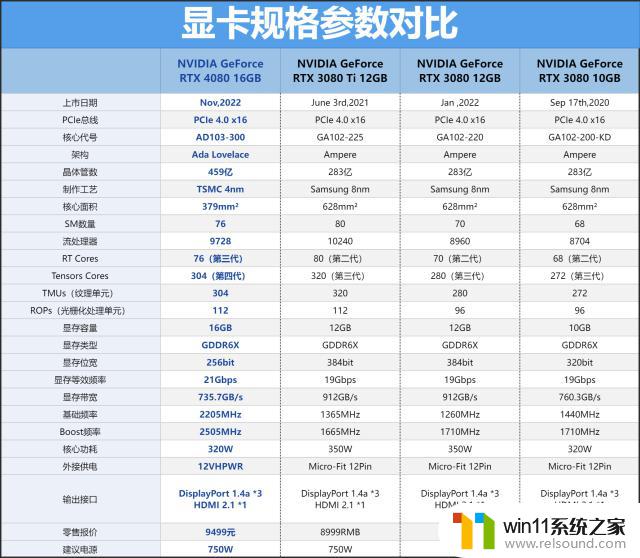
再来对比一下30系列时代同定位的RTX3080Ti显卡,RTX408016GB其实并没有规格上的优势,甚至还有一些低了?错了,RTX408016GB是甚至AdaLovelace架构核心,而RTX3080Ti却是Ampere架构的显卡,两者从架构上就不对比,而RTX4090首发时也表明AdaLovelace架构有着更先进的设计、更高的性能表现。

同时RTX408016GB采用了选进的TSMC4n工艺,内部的晶体管数量已经达到了459亿,比RTX3080Ti高多了,但是其设计功耗也仅是320W,所以每瓦性能比上来看RTX408016GB相信会比RTX3080Ti好不少,那实测是否真是如此呢,我们就去看一下。
2RTX 4080 FE显卡
GeForceRTX4090FounderEdition外观

从外观上来看,RTX408016GBFE采用了RTX4090FE同款的外观设计,其实不单是外包装,设计元素,甚至是散热器做弄等,与散热直接就是RTX4090FE基本就是一个模样,因此很容易让人误认为此款为RTX4090FE显卡。

但实际上看背面与小标签就知道,这其实是RTX408016GBFE显卡,毕竟背部有着那么明显的RTX4080产品型号标识。

两块显卡放到一起就会发现什么叫真正的1:1,初步来看这套散热器方案与RTX4090FE是一样的,设计之初其实是为了600WTDP散热而来,但是现在用到RTX4090上很是冷快,那么直接套到RTX408016GBFE显卡,也就意味着此款显卡的散热会有相当不错的效果。

前面的RTX4080小标还是比较好看的,


从30系列FE公版显卡开始,FE公版就是默认采用前后两把的轴流风扇设计,两把12cm风扇均PWM控制,低转速时噪音和风量控制都相当好。

输出接口方面,当然是同一套的3*DP1.4a+1*HDMI2.1接口,单接口最高支持4K144Hz,多屏最多支持3+1屏输出。
GeForceRTX4090FounderEdition,PCB

RTX4090FrontPCB
由于特殊原因,此次我们并没有对GeForceRTX408016GBFE显卡进行拆解,我们直接拿NVIDIA提供的PCB图来了解显卡的内部设计。

GeForceRTX408016GBFEPCB
首先我们可以看到AD103核心采用的是中型核心设计,所以核心尺寸上得比AD102核心得小巧多了;同样由于显存位宽的限制所以GeForceRTX408016GBFE显存仅配合了PCB正面8颗GDDR6X显存颗粒,组成16GB/256Bit规格,显存带宽达到了716.8GB/s。
而供电设计方向,由于GeForceRTX408016GBTDP设计功耗为320W(FEMaximunTDP为355W),所以在供电方面进行了一定的削减(PCB供电有部分空焊位置),采用了12相核心+4相显存的供电设计,而空焊的位置其实是为了满足更高核心规格、更高频率的AD103而设计。你看同时发布的几家AIC非公RTX4080显卡的供电就知道了,基本就是照着RTX4090供电规格去弄的,只等NVIDIA释放更高功耗设计的BIOS了。

散热方面还是NVIDIA标志性的双轴流风扇散热模块,整个散热模块均为大面积的黑化散热鳍片与多热管的设计。
3测试平台介绍
测试平台介绍:


此次测试平台我们不再使用RTX4090首发时的那套,而是更换成了英特尔最新的13代酷睿i9-13900K处理器,此款处理器因为有着更高的频率与更多的核心数量,所以在游戏与内容创作方面都处于目前桌面级市场上顶级的水平。

而配合上旗舰级的处理器,我们拿来的四条KingstonFURYRenegadeDDR5RGB内存,并手动降频运行在DDR5-6000C32,Gear2模式下,这样可以确保平台有着更佳性能的同时也有着更高的稳定性。

显卡方面,我们拿来了上代同定位的RTX3080TiFE、RTX4090FE两款公版显卡与这次首发对象RTX4080FE显卡进行对比测试,包括理论性能表现,内容创作能力,游戏性能,DLSS测试,功耗对比,以及超频测试。
显示器方面自然是评测室专用的电竞神器——爱攻&保时捷联名PD32M4K144电竞显示器,配合上RTX4080FE显卡相信会有着更佳的游戏体验。
同样的在测试前,我们得先确保一下系统配置是正确的,因为上次RTX4090首发时就知道,需要在系统和BIOS中进行一定的配置才能开启上DLSS2功能。同时NVIDIA的技术指导文档中已经说到,想要开启DLSS3功能,需要几个步骤:
将硬件加速的GPU调度设置为开启
以全屏模式运行游戏以获得最佳性能和最低延迟。
请确保在NVIDIA控制面板中将显示器设置为最大刷新率。
建议使用G-SYNCUltimate显示器进行最佳体验评估。
在主板的SBIOS中开启ResizableBAR。
4理论性能&内容创作测试
理论性能测试:
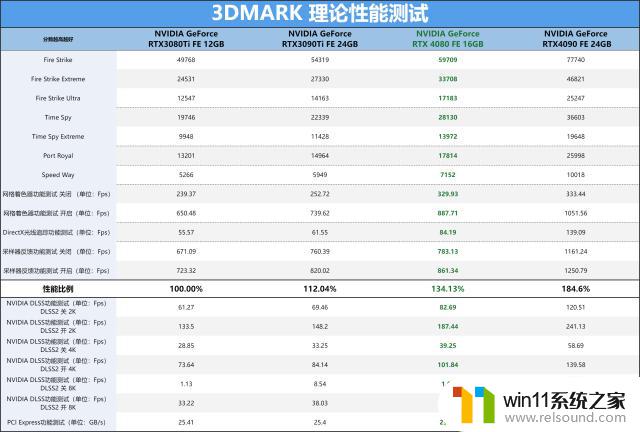
理论性能我们主要是以3DMARK测试为主,由FireStrike、TimeSpy、PortRoyal、SpeedWay等进行显卡性能测试,而其它的测试小项为辅。尤其是PortRoyal与新增的SpeedWay主要反馈的是显卡的光线追踪性能。
小结:可看到RTX40系列显卡的性能水平基本就是提升了一个台阶,单纯的拿3DMARK跑分来说,RTX408016GB理论性能都要比RTX3090Ti好,更不用说RTX3080Ti此款显卡了。
当然与旗舰级的RTX4090差跑还是有较为明显的理论性能差别,毕竟CUDA核心、RTCores、TensorCores,甚至是显存位宽这些都差距有点明显,这样的理论性能表现也是能接受的,就看真实的性能会是如何了。
AIDA64GPGPU测试
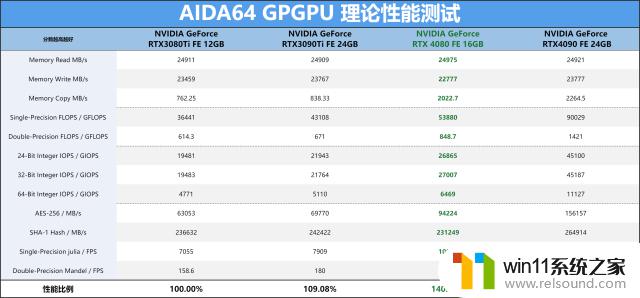
GPGPU理论性能测试方面其实很好的表明了这一代的RTX40系列显卡在算力上有着较为出色的性能表现。这次RTX4080的性能表现还是不错的,中型核心就已经优势于上代的大型核心,每W性能比提升不少。
创作者能力测试:
视频与平面内容创作方面这次我们测试得比较多,包括了PCMark10与PugetBench三个大项,其中PugetBench其实把PS|PR|LR|AE|达芬奇这五款较为常见的软件都测试了篇。ADOBE软件使用的是最新的ADOBE2023版本,而达芬奇是NVIDIA提供的AV1特殊版本。
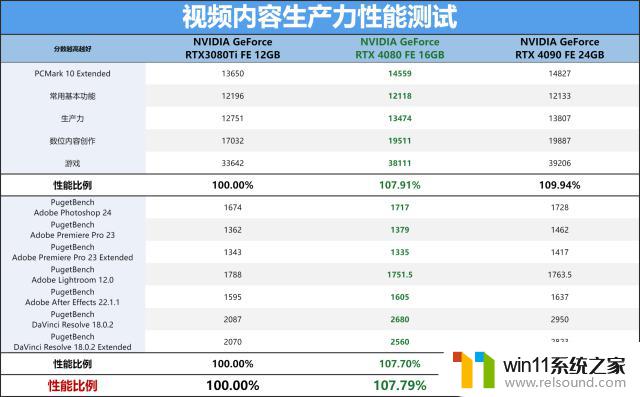
PCMARK10测试中反馈的是整机的性能,所以大家可认真看看子测试项目上,提升较大的同样是游戏方面。
而PugetBench方面我们更新到了最新版本的脚本,能够支持最新的ADOBE2023版本软件,按照性能比例来说,RTX4080FE比RTX3080Ti提升约为7%,同样比RTX4090的弱一些。性能差别较大的是达芬奇的测试上,使用的版本为18.0.2,性能提升达到了125%。但是ADOBE全家桶的性能表现其实并不太理想,总感觉优化不太到位,反而对旧显卡RTX3080Ti的优化就相当可以。之后ADOBE推出更新的版本,或者是NVIDIA推出正式版本驱动后我们再来测试一翻。
专业设计领域
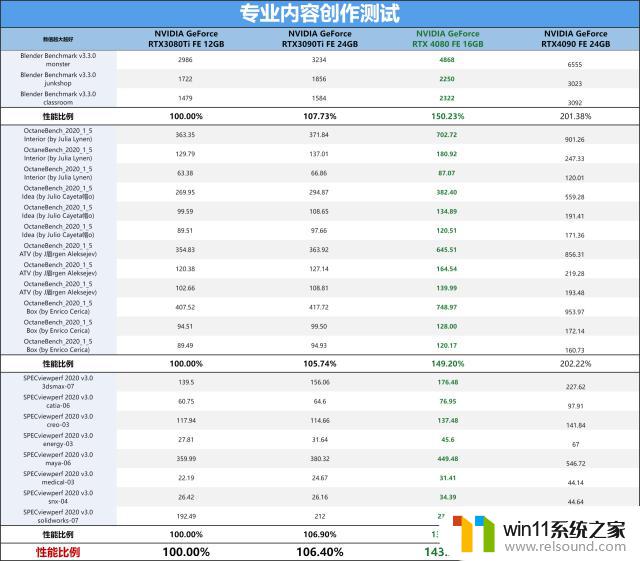
专业设计领域领域测试中,RTX40系列显卡真是专门为了专业内容领域而来的,整个性能表现提升还真的很强。尤其是旗舰级别的RTX4090能达到190%性能提升,而RTX4080也有143%性能提升,比上代RTX30系列旗舰都强得多了。
AV1能力测试:
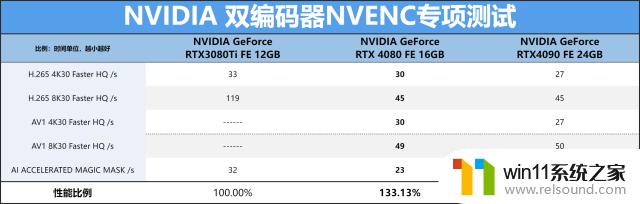
虽然说RTX408016GBFE显卡中少了三个NVDEC单元,但是NVENC单元仍是保留两个的,对于AV1这个新格式来说还是完全没问题。我们同样利用上次RTX4090首发时的达芬奇Prores422HQtoAv1EncodeTest项目文件进行测试,同样tearsofsteel_8k_proRes422HQ视频源,我们测试【H.2658K30】项目下的RTX4080FE导出速度比RTX3080TiFE快1.6倍。
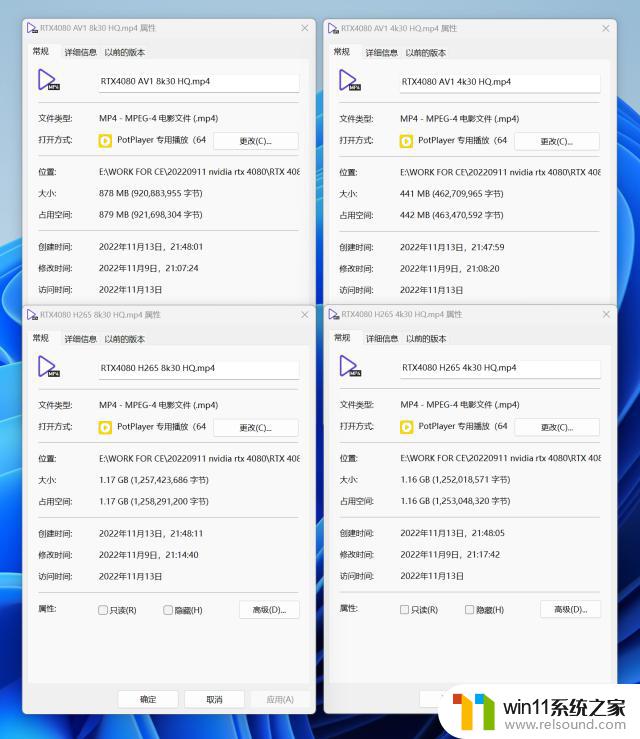
另外可看到AV1格式的确是比H.265格式省空间多了,AV18K30视频也就800多MB,AV14K30也就400多MB;而H.265两个分辨率的格式都得去到1.16GB,这一对比容量差别是真大了。

我们再来看看H.265格式与AV1格式画质上的差别,同样是拿8K30的视频抽取三个不同的时间节点,且100%放大后对比,从肉眼来看,其实就是一样的。这样也意味着即使是AV1与H.265有着同样的画质表现,但是所占的空间容量更低。配合上RTX40系列显卡导出AV1格式有着时间、容量以及画质上的优势。
5游戏性能测试
游戏性能测试:
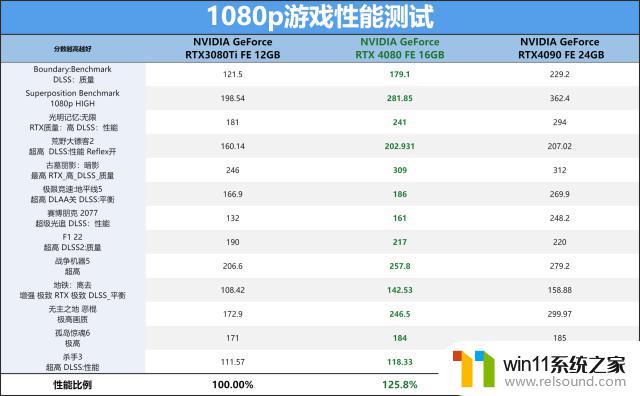
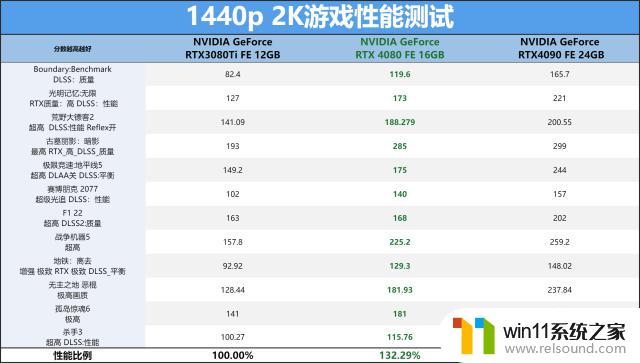
对于这个次旗舰级别的显卡来看,1080p与2K分辨率的游戏其实全都没有压力的,就看其RTX4080能提升多少游戏流畅度了。RTX4080FE应对市面上的3A游戏完全是没有压力的,基本能上120FPS以上来跑,部分游戏更是达到了200FPS+的水平,比上代RTX3080Ti快了25%以上。
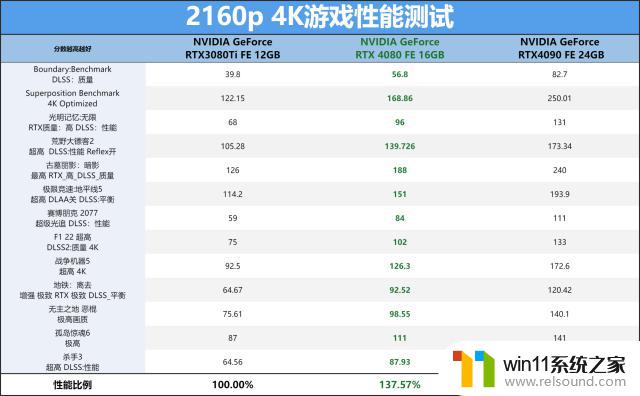
而随着分辨率的逐步提升,RTX4080FE逐步拉开了与RTX3080Ti的差距,4K分辨率下达到了37%的流畅度提升。同样大部分的3A游戏都能保持在超高的流畅度,4K144的电竞梦这次不用再等RTX4090显卡来实现了,一块RTX4080显卡即可以满足。
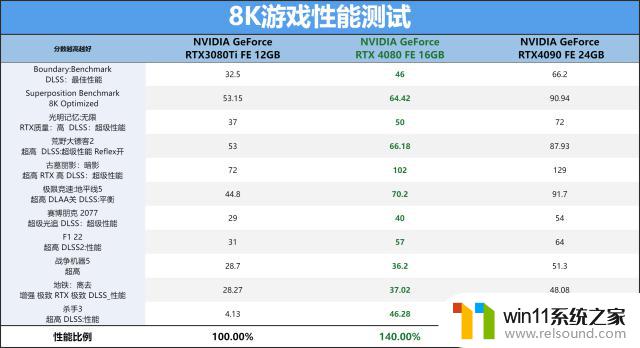
而8K的情况下,只有RTX4090才能真正满足全部的3A游戏高画质的要求了,RTX408016GB其实我们降低一些画质即可以满足8K60基本的游戏度运行,同样的RTX4080比上代RTX3080Ti提升了约40%。
6DLSS3性能测试
DLSS3性能测试:
自RTX4090显卡发布之后越来越多的游戏都支持上了DLSS3这一新技术,而来到11月15日GeForceRTX4080发售时,将已有10款DLSS3游戏发布
1.《瘟疫传说:安魂曲》(APlagueTale:Requiem)
2.《光明记忆:无限》(BrightMemory:Infinite)
3.《毁灭全人类2:重新探测》(DestroyAllHumans!2-Reprobed)
4.《暗影火炬城》(F.I.S.T.:ForgedinShadowTorch)
5.F1®22
6.《逆水寒》(Justice)
7.《生死轮回》(Loopmancer)
8.《漫威蜘蛛侠:重制版》(Marvel’sSpider-ManRemastered)
9.《微软模拟飞行》(MicrosoftFlightSimulator)
10.《超级人类》(SUPERPEOPLE)
而这次DLSS3测试中,我们挑选了这里面的6款游戏,配合上UE5引擎的两个BENCHMARK与赛博朋克2077DLSS3内测游戏RTX408016GB的显存性能测试。
哦对了,在DLSS3的游戏测试之前我们仍是先来看看DLSS3的理论性能表现,这里我们直接使用的是最新版本的3DMARK理论性能测试软件,内部集成了一个最新的DLSS3测试程序。
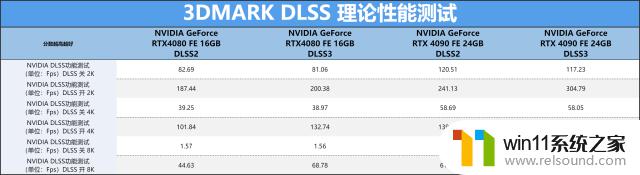
但是由于目前只有两款显卡支持最新的DLSS3技术,所以下面的测试我们基本都是拿RTX4090FE显卡与RTX408016GBFE进行性能对比。从数据上来看,RTX4090FE果真对得起旗舰级的称号,在不开启DLSS功能下的基础性能就已经相当出色,当然RTX4080也不弱4K分辨率光线追踪的仍能跑到39FPS,在开启DLSS2游戏帧数更是明显直接直长号䭴101FPS,而在DLSS3技术加持下,已经达到了132FPS超级流畅的水平。同时可看到随着分辨率不断增加,DLSS3功能对游戏流畅度的提供就越来越明显,尤其是8K分辨率下,本只能玩2FPS,结果直接跑到了69FPS,这提升是真的相当显著。
UnrealEngine5EnemiesDEMO

看数据估计大家都会觉得沉闷,这里我们做了一些小视频给大家参考。Enemies是NVIDIA提供给媒体与各大KOL测试所用的DEMO,利用UnrealEngine5轻松制作了一个数字人类,第一次接触这个DEMO的时候还真的相当的惊讶,原来UnrealEngine5已经可以这么强劲。
另外值得我们注意的是这个DEMO是带上DLSS3,兼容DLSS2技术的,那我们通过开启DLSS3与关闭DLSS就可看到DEMO里FPS值的变化是不一样的,4K分辨率下RTX4080可达77AVG/661%FPS/55ms的水平,而关闭DLSS3后仅有22AVG/171%FPS/195ms,基本就是3.5倍的游戏流畅度提升。
《光明记忆:无限》(BrightMemory:Infinite)
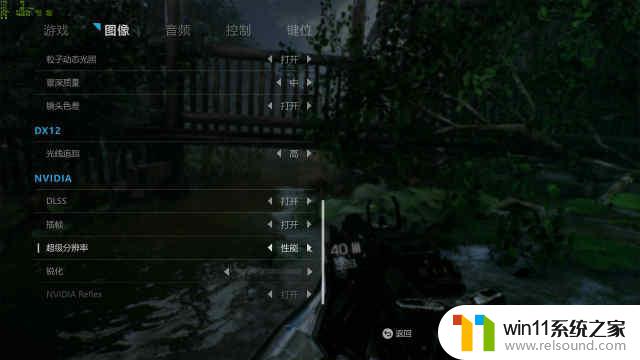
《光明记忆:无限》(BrightMemory:Infinite)之前RTX4090首发的时候是利用beta版本的,而RTX4080首发时我们就此款《光明记忆:无限》游戏就已经支持DLSS3技术,并且我们还能在游戏中通过开启DLSS3的【插帧】来实现DLSS2与DLSS3。

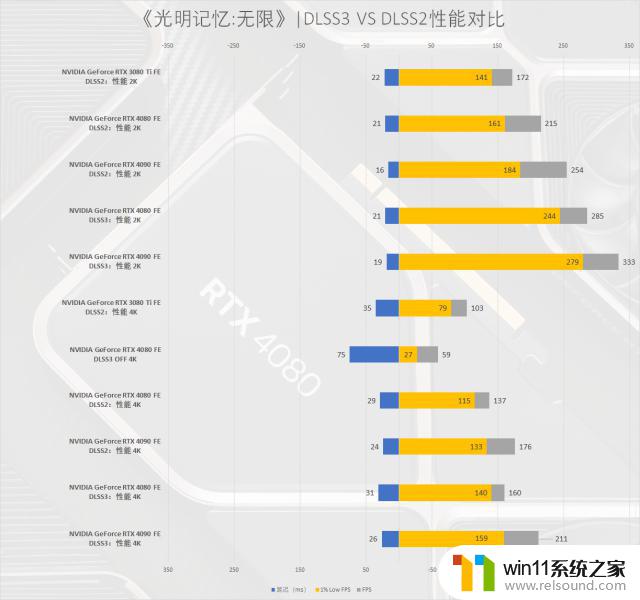
同样的,其实在不开启DLSS的情况下,RTX408016GBFE显卡在4K分辨率下仍是可以流畅运行《光明记忆:无限》此款游戏;但是开启DLSS2功能后,游戏帧数就达到了137,1%帧数也达到了115FPS,这完全就是翻倍的游戏流畅度提升嘛;至于开启DLSS3之后,那么游戏帧数更是达到了160FPS,配上目前游戏的4K144显卡,例如我们测试中使用的AGONPD32M,玩此款游戏那是真爽了。
再分享一个笔者在游戏开头找杀了几个对手之后《光明记忆:无限》游戏里开启DLSS3游戏的效果,分辨率为4K,画质极高,DLSS模式为性能。
2K分辨率与4K分辨率DLSS性能测试
DLSS3的性能测试我们这里做了两个分辨率与十个项目,这里就不再单一的说了,笔者弄个汇总的表格给大家作参考之用吧。注意:DEMO里是没帧生成开关的,所以30系列显卡其实运行在DLSS2模式之下。
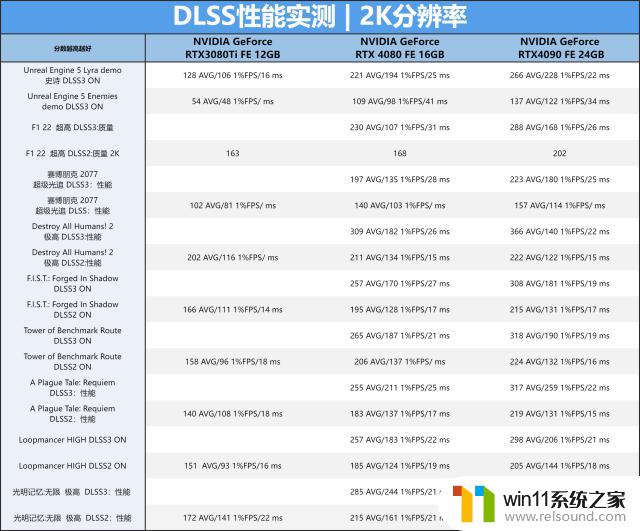
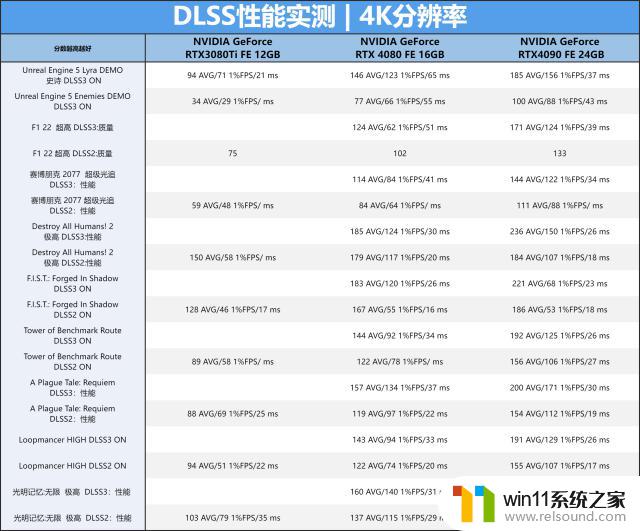
2K分辨率与4K分辨率两者的表格其实都表明,基于新一代AdaLovelace架构的RTX408016GBFE显卡在DLSS2功能的加持下就有着比上代RTX3080TiFE更高的游戏流畅度,而开启40系列显卡独有的DLSS3功能后,游戏流畅度进一步的提供,基本可以实在4K144,2K180以上的水平,40系列显卡真强果真不是吹的。
8K分辨率
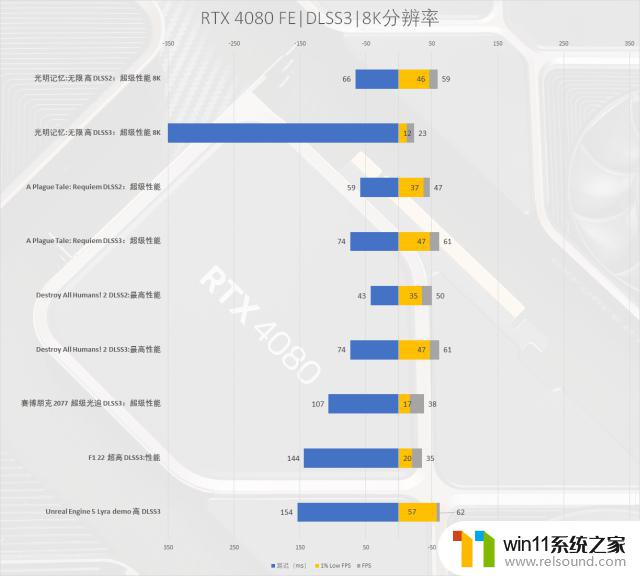
当然其实我们也用RTX4080FE测试了8KDLSS3游戏的性能表现,同时我们也遇到了爆显存的情况,主要表现为显存占用达到了16GB,游戏帧数也较低。只能说老黄的刀法是真可以,刚好16GB这个就爆了,或者之后在游戏厂商的优化下,可以降低更少的显存占用。
值得注意的是RTX4080FE其实在DLSS3功能的加持下都能使用8K60这样的游戏帐,刚好配上目前的8K显示器,甚至是8K电视也是不错的。
而在RTX4080推出后不久,WRCGenerations,《极品飞车:不羁》(NeedforSpeedUnbound)和《战锤40K:暗潮》(Warhammer40,000:Darktide)等三款游戏也将会发布,圣诞节前玩家就可畅玩这些DLSS3游戏。
了解关于DLSS3更新:https://www.nvidia.com/en-us/geforce/news/more-november-2022-rtx-dlss-game-updates
7温度&功耗
温度与功耗测试:
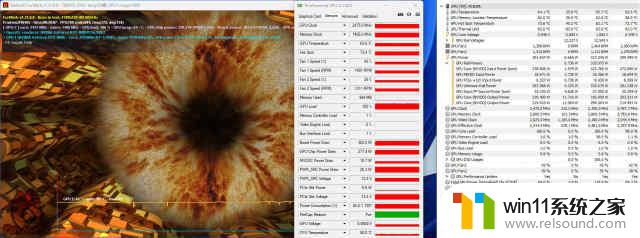
烤机方面我们同样利用FURMARK软件进行重负载的烤机测试,经常20分钟的烤机,显卡最终核心温度稳定在63度,显存温度为60度,此时核心频率仍能运行在2475MHz高频下,GPU功耗达到了302W;从HWINFO64上来看,PCI-E供电仅提供了6.6W,主要的供电来源为+12V辅助供电上,达到了298W。同时此时的风扇转带最高仅是43%,噪音表现相当出色。
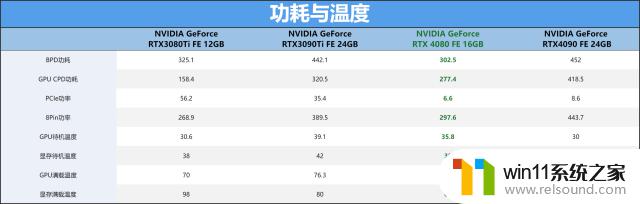
横向对比一下上代显卡与RTX4090显卡的功耗,从功耗来看,其实RTX4080功耗控制还是相当不错的,最高才是300W还比RTX3080Ti少多了,而且性能更强了。
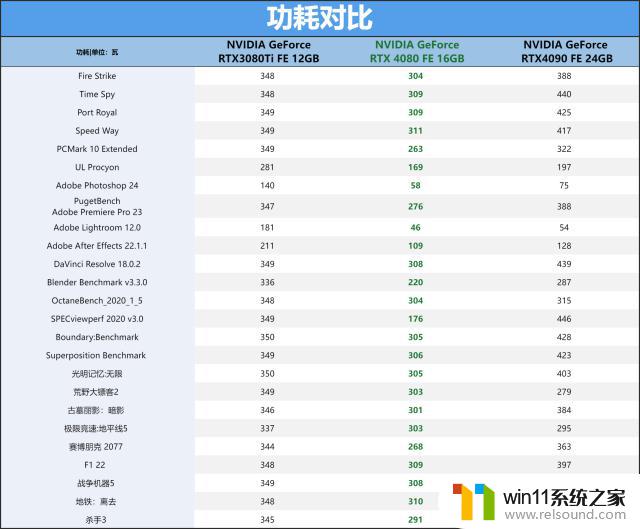
测试的时候其实我们同时利用HWINFO64在后台进行功耗记录,结果如上图一样,RTX3080Ti基本跑的是350W,而RTX408016GBFE也就300W左右,部分应用软件上甚至更低的功耗表现。所以说RTX408016GB每瓦性能比是实打实的提升到了一个新高度。
8超频能力&总结
超频能力测试:
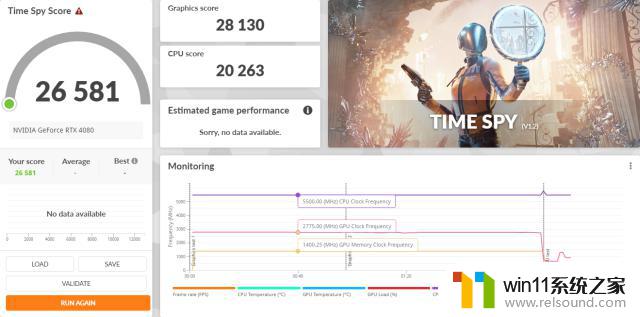
RTX408016GBFE显卡在TimeSpy测试中的默认得分为28130,其40秒的核心频率为2775MHz。
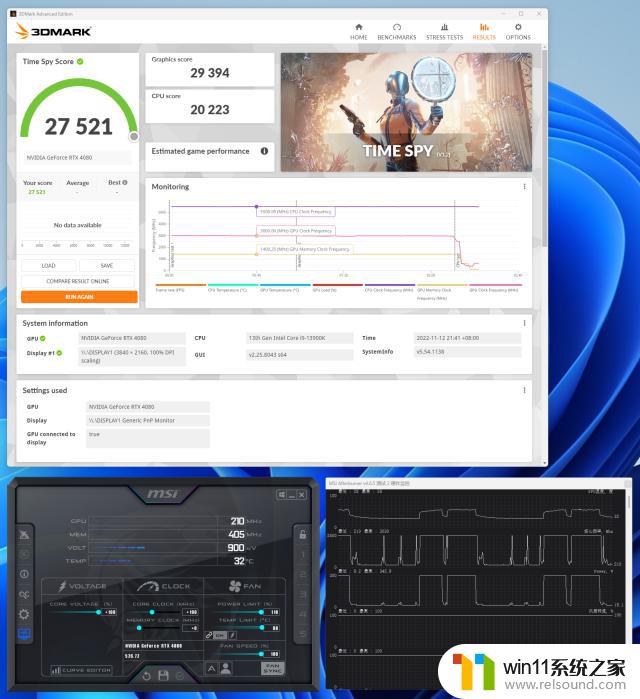
利用MSIAfterburner软件对RTX408016GBFE显卡进行超频,先把功耗与温度的限制拉到最高,同时把电压解锁到100%,这样我们就可以对显卡进行超频了。核心+190MHz,TimeSpy测试中的默认得分为29394,其40秒的核心频率为3000MHz。
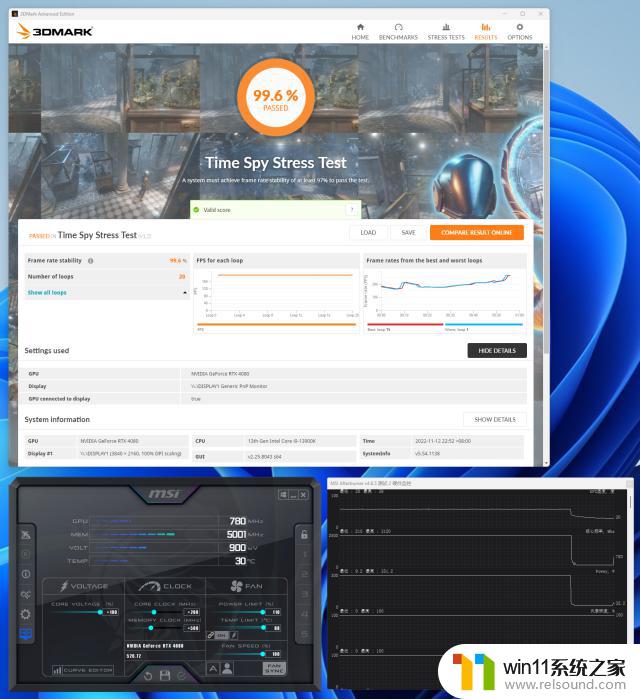
随后我们直接把核心+200MHz,显存+500MHz,这时候核心在运行TimeSpy测试的频率已经达到了3000MHz,直接通过了TimeSpy压力测试。
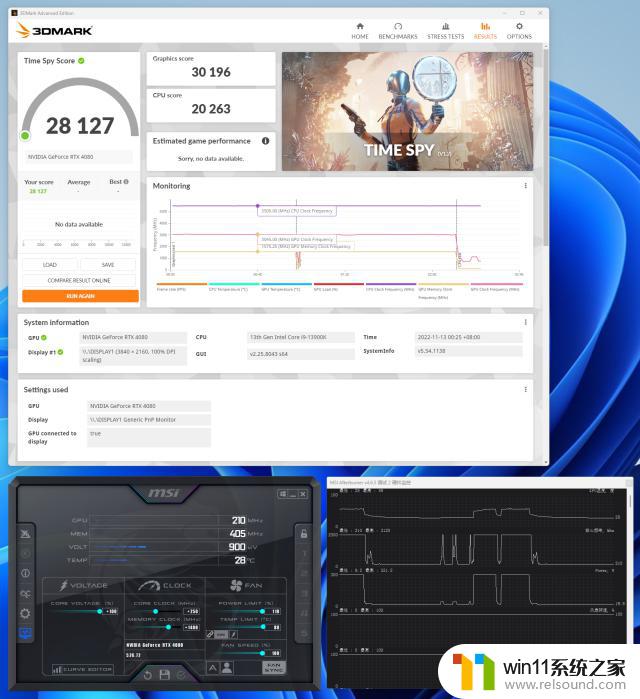
最高核心频率只能控制在核心+250MHz,显存+1400MHz,TimeSpy测试中的默认得分为30196,其40秒的核心频率为3045MHz,显存频率为1575.25MHz,相比默认频率提升了7.3%。
小结:RTX408016GBFE显卡起步潜力其实相当强,但是我们利用HWINFO64在旁监测,核心与显存超频后最高TDP被限制在了350W。相信一些AIC厂商在更强供电规模的情况下,有着更进一步的超频潜力。
总结:

对于一款定位次旗舰的显卡来说,RTX408016GB性能表现的确是比较养眼的,无论是理论性能,常规游戏,还是支持DLSS3的最新游戏,RTX4080在多个分辨率下都有着较为出色的性能表现。尤其是在DLSS3的加持下,分辨率越高比上代RTX3080Ti性能提升就越大,即使是4K分辨率也能享受120Hz流畅丝滑的体验,甚至你降低画质也能在8K分辨率上体验到60FPS。

至于创作者能力上,RTX408016GB仍给我们较为满意的答案,专业领域方面性能上的提升甚至比上代30系列旗舰都要比下去,专业用户也可以享受到更为全面的提升。果然RTX40系列显卡是冲着专业用户而来的。
当然如果是你小视频工作室,那么此款显卡也会是不错的选择,AV1的加持与NVIDIA双编码器技术的应用越来越多,在同画质的情况下,编码导出时间更快,占用容量更低。
最后自然是价格,RTX408016GBFE零售报价9499元,这价看着不低但开卖的时候大家还是很实诚的,你看当时RTX409024GBFE直接买断货就是同样的道理,相信RTX408016GBFE同样会被买断,毕竟性能、功耗、温度这三者就已经比目前同档次的显卡都要好。
9ADA架构回顾
技术回顾:AdaLovelace架构优势
Turing、Ampere上两代架构核心均以人物来命名,前者是计算机科学之父——艾伦·麦席森·图灵;后者则是“电学中的牛顿”——安德烈·玛丽·安培,电流的国际单位安培就是以其姓氏命名。那AdaLovelace定非凡人,度娘一下果然,这是 人称“数字女王”的阿达·洛芙莱斯,编写了历史上首款电脑程序,是被世界公认的第一位计算机程序员,果真是一代比一代还要更牛。PS:她的父亲是《唐璜》的作者,诗人拜伦喔。
从Turing架构开始,NVIDIA首次在显卡中加入了加速光线追踪的RTCore单元,以及面向AI推理的TensorCore单元,这革命性的创新使实时光线追踪成为可能。而Ampere架构则是全面的架构改进,在加入新一代的二代RTCore和三代TensorCore基础上,还有着更先进的SM单元设计,这样显卡工作效率那是翻倍的提升。而来到AdaLovelace架构,同时是以效率提升为大前提,自然是引入了最新的第三代RTCores与第四代TensorCores单元,同时加入众多新颖的黑科技,从执行效率来说AdaLovelace架构是上代Ampere架构的2倍以上,甚至光线追踪能力更是达到了恐怖的4倍性能。
全新的SM流式多处理器
AdaLovelace架构中最大的亮点之一:全新的SM流式多处理器,每个SM包含了128个CUDA核心、1个第三代的RTCores,4个第四代TensorCores(张量核心)、4个TextureUnits(纹理单元)、256KBRegisterFile(寄存器堆)。以及128KBL1数据缓存/共享内存子系统,于是这一个全新的SM单元有着超过上一代2倍之的性能表现。
过去的Turing架构INT32计算单元与FP32数量是一致的,而两者相加才组成了64个CUDA核心。但是Ampere架构开始,左侧的计算单元实现了FP32+INT32的计算单元并发执行,也就是说CUDA核心数量翻倍到了128个。
再来看看AdaLovelace架构的SM,FP32/INT32的计算单元组合,同样实现了每个SM内含128个CUDA的设计,看似提升不大,但是当你了解到GeForceRTX4090拥有128个SM,16384个CUDA核心,那你也就应该明白达82.6TFLOPS的着色器能力是如何实现的了,比上一代的RTX3090Ti显卡的40TFLOPS,还真是提升了两倍有多。
另外缓存方面AdaLovelace架构也进行了大规格的提升,首先每个SM单元中单独配上了128KB的缓存,这样RTX4090/RTX4080显卡中就实现了更大的L1/共享内存以及更大的L2缓存,因此AdaLovelace架构核心对显存位宽的依赖性并不高。
技术讲解:第三代RTCores与第四代TensorCores
以为刚才的CUDA数量与超大L2缓存就已经很猛了,实现上AdaLovelace架构最大的提升还是在第三代RTCores与第四代TensorCores身上。
第三代RTCores
RTCores用于光线追踪加速,第三代RTCores的有效光线追踪计算能力达到191TFLOPS,是上一代产品2.8倍。
在Ampere架构中,第二代RTCores支持边界交叉测试(BoxIntersectiontesting)和三角形交叉测试(TriangleIntersectiontesting)。用于加速BVH遍历和执行射线三角交叉测试计算,虽然光线追踪处理能力已经比初代的Turing架构核心更高效,但是随着环境和物体的几何复杂性持续增加,传统的处理方式很难再以更高效率、正确反应出的现实世界中的光线,尤其是光的运动准确性。
所以在第三代RTCores增加了两个重要硬件单元:OpacityMicromapEngine与DisplacedMicro-MeshesEngine引擎。OpacityMicromapEngine,主要是用于alpha通道的加速,可以将alpha测试几何体的光线追踪速度提高2倍。
在传统光栅渲染中,开发人员使用一些Alpha通道的素材来实现更高效的画面渲染,例如Alpha通道的叶子或火焰等复杂形状的物体。但在光线追踪时代,这传统的做法会为光线追踪带为不少无效的计算,例如运动性的光线多次通过一块叶子,光线每击中一次叶子,都会调用一次着色器来确定如何处理相交,这时就会做成严重的执行成本与时间等待成本。
而OpacityMicromapEngine用于直接解析具有非不透明度光线交集的不透明度状态
三角形。根据Alpha通道的不透明,透明与未知等三个不同的块状态进行处理:透明则直接忽略继续找下一个,不透明块则记录并告之命中,而未知的则交给着色器来确定如何处理,这样GPU很大部分都不需要进行着色器的调试处理,能够实现更为高效的性能。
DisplacedMicro-MeshesEngine
如果说OpacityMicromapEngine加速的是面处理,那么DisplacedMicro-MeshesEngine就是几何曲面细节的加速器。如上图所示,在AdaLovelace架构中,通过1个基底三角形+位移地图,就可以创建出一个高度详细的几何网格,所需要资源占用比二代RTCores更低,效率也更高。
通过NVIDIA给出的创建14:1珊瑚蟹例子来说事,这里我们需要需要1.7万个微网格、160万个微三角形,在AdaLovelace架构中BVH创建速度可加快7.6倍,存储空间缩小8.1倍。DisplacedMicro-MeshesEngine起到了关键性的作用,其将一个几何物体根据不同细节分成密度不一的微网络处理,红色密度超高,细节处理越为复杂。相应的低密度微网络区域则可以释放更多的资源与存储空间,这样DisplacedMicro-MeshesEngine就可以帮助BVH加速过程,减少构建时间和存储成本。
同时AdaLovelace架构SM中新增了着色器执行重排序(ShaderExecutionReordering,SER),这是由于光线追踪不再只有强光或者阴影渲染处理,未来将会更多的是在光线的运动性,这样光线就会变得越来越复杂,想要第三代RTCores与第四代TensorCores有着更高的执行效率,那就得为他们来安排一位管家。而着色器执行重排序(SER)就是为了能够即时重新安排着色器负载来提高执行效率,为光线追踪提供2倍的加速,也能更好地利用GPU资源。不过目前仍未有实例,想实现这个功能,还得游戏与开发工具的支持才行。
第四代TensorCores
TensorCores是专门为执行张量/矩阵运算而设计的专用执行单元,这些运算是深度学习中使用的核心计算功能。第四代TensorCores新增FP8引擎,具有高达1.32petaflops的张量处理性能,超过上一代的5倍。
技术讲解:DLSS3
或者说第四代TensorCores太硬核你不会知道是啥?提升意义在哪?但是TensorCores最经典的应用DLSS你肯定会知道,这一次AdaLovelace架构支持NVIDIA最新的DLSS3技术。
之前我们也聊过DLSS技术,其设计之初是为了弥补光线追踪技术后的性能损失,具体的表现为开启光线追踪技术后游戏帧数大幅度的下降,甚至很难保证游戏流畅的运行。于是DLSS使用低分辨率内容作为输入并运用AI技术输出高分辨率帧,从而提升光线追踪的性能。
在DLSS3中包含了三项技术:DLSS帧生成、DLSS超分辨率(也称为DLSS2)和NVIDIAReflex。你可以理解为DLSS3是在DLSS2的基础上,新增了DLSS帧生成技术;而后两技术中,DLSS超分辨率只需要GeForceRTX显卡都能使用上,NVIDIAReflex则是GeForce900系列以后的显卡都用使用上。
想实现DLSS帧生成可不简单,这需要配合上AdaLovelace架构的GeForceRTX40系列显卡才行。DLSS帧生成技术原理是:利用AI技术生成更多帧,以此提升性能。DLSS会借助GeForceRTX40系列GPU所搭载的全新光流加速器分析连续帧和运动数据,进而创建其他高质量帧,同时不会影响图像质量和响应速度。
从Ampere架构开始,NVIDIA显卡就已经支持了光流加速器,而AdaLovelace架构的光流加速器升级到了第二代,其提供了高达300TeraOPS(TOPS),比安培架构的初代光流加速器(OpticalFlowAcceleration,OFA)快2倍以上。为了实现DLSS帧生成,OFA扮演了重要的角色,其配合上新的运行⽮量分析算法在DLSS3技术框架内实现精确和高性能的帧生成能力。
另外,由于DLSS帧生成是在GPU上作为后处理执行的,那么即使在游戏受到CPU性能限制的时候,我们同样能够从中获得更好的游戏性能提升。尤其是那种物理计算密集型的游戏或大型场景游戏,DLSS2均可以让GeForceRTX40系列显卡以高达两倍于CPU可计算的性能来渲染游戏。
最后由于DLSS3是建立在DLSS2基础之上的,游戏开发者可以在已支持DLSS2或NVIDIAStreamline的现有游戏中快速集成该功能,所以DLSS3已在游戏生态得到广泛应用,目前已有超过35款游戏和应用即将支持该技术。
阅读小亮点:NVIDIAReflex
NVIDIAReflex也是DLSS3其中的一环,它可以使GPU和CPU同步,确保最佳响应速度和低系统延迟。
想要实现端对端的最低延迟,你需要确保游戏、显示器以及鼠标三者都同时支持并开启了Reflex技术。
当GeForceRTX40系列显卡和NVIDIAReflex搭配上后,直接达到1440p分辨率360FPS的体验,这着实是性能有点强劲了。
在GTC2022大会时已经透露将会还有4款1440p分辨率的新型G-SYNC电竞显示器将要发布,包括采用mini-LED技术的AOCAG274QGM–AGONPROMiniLED、MSIMEG271QMiniLED和ViewSonicXG272G-2KMiniLED三款显示器刷新率均为300Hz。而最猛的是ASUSROGSwift360HzPG27AQN,刷新率直接来到了360Hz。
技术讲解:双NVIDIA编码器(NVENC)
GeForceRTX40系列显卡还有一个全新的升级,那就是双编码器NVENC。第八代的NVENC双编码器不仅支持H.264与H.265,还支持开放式视频编码格式AV1。
而由于AV1是一种免版税的视频编码格式,上游软件厂商与下游戏的配套端都在大力推广此编码格式,我们也会看到越来越多的硬件与软件支持AV1格式,包括剪映专业版、DaVinciResolve、以及AdobePremierePro较为流行的Voukoder插件均支持,且均可通过编码预设使用双编码器,这样我们等待视频导出的时间缩短将近一半。
不单是视频制作软件,AV1格式也将会是主播、游戏直播UP主们的新宠儿,在保证画面最高质量的情况下,AV1编码器可将效率提高40%,同时显卡的占用也更低。包括OBSStudio一一代软件中也会增加AV1格式的支持。另外我们还能通过GeForceExperience和OBSStudio录制高达8K60的内容,这样我们做游戏录制也会变得更为轻松。
包括我们之后测试时使用的游戏内录视频都是支持AV1格式,同时双编码器NVENC在资源占用和适配上做得越来越好。
NVIDIA GeForce RTX 4080 FE公版首发评测:ADA架构第二发炮弹如何表现?相关教程
- 评测室微软Surface Laptop第7版15英寸首发体验:性能体验如何?
- NVIDIA发布Ada Lovelace架构GeForce RTX 4060系列,价格从2399元起
- 游戏核武器:AMD 锐龙7 9800X3D处理器首发评测,性能如何?
- 发烧游戏玩家的唯一选择!AMD锐龙7 7800X3D首发评测
- 颜值出色创作神器:iGame GeForce RTX 4070 Advanced OC显卡首发评测
- AMD Radeon RX 6X50系列显卡首发评测:性能提升符合预期
- 英特尔锐炫A380显卡:挑战蓝色巨人,桌面独显市场首发评测
- AMD Radeon RX 7600独立显卡首发评测-甜品卡大混战谁是最强王者?
- DLSS 3与AI让体验成倍提升:英伟达GeForce RTX 4070显卡首发评测
- NVIDIA GeForce RTX 4060 Ti FE显卡首发评测:DLSS 3畅玩1080P光追
- 英伟达新一代AI芯片过热延迟交付?公司回应称“客户还在抢”
- 全球第二大显卡制造商,要离开中国了?疑似受全球芯片短缺影响
- 国外芯片漏洞频发,国产CPU替代加速,如何保障信息安全?
- 如何有效解决CPU温度过高问题的实用方法,让你的电脑更稳定运行
- 如何下载和安装NVIDIA控制面板的详细步骤指南: 一步步教你轻松完成
- 从速度和精度角度的 FP8 vs INT8 的全面解析:哪个更适合你的应用需求?
微软资讯推荐
- 1 英伟达新一代AI芯片过热延迟交付?公司回应称“客户还在抢”
- 2 微软Win11将为开始菜单/任务栏应用添加分享功能,让你的操作更便捷!
- 3 2025年AMD移动处理器规格曝光:AI性能重点提升
- 4 高通Oryon CPU有多强?它或将改变许多行业
- 5 太强了!十多行代码直接让AMD FSR2性能暴涨2倍多,性能提升神速!
- 6 当下现役显卡推荐游戏性能排行榜(英伟达篇)!——最新英伟达显卡游戏性能排名
- 7 微软发布Win11 Beta 22635.4440预览版:重构Windows Hello,全面优化用户生物识别体验
- 8 抓紧升级Win11 微软明年正式终止对Win10的支持,Win10用户赶紧行动
- 9 聊聊英特尔与AMD各自不同的CPU整合思路及性能对比
- 10 AMD锐龙7 9800X3D处理器开盖,CCD顶部无3D缓存芯片揭秘
win10系统推荐